Details about the competition can be found in this paper and these slides.
How the success of the learning is evaluated
As the participants submit a ranking of potential 5 next symbols, meaning they give an ordered list of 5 symbols starting from the most probable next symbol, we are using a ranking metric based on normalized discounted cumulative gain.
Suppose the test set is made of prefixes y1, ..., yM. Suppose now that the distinct next symbols ranking submitted for yi is (â1i, ..., â5i) sorted from more likely to less likely.
As we have access to p(.|yi), the target probability distribution of possible next symbols knowing the prefix yi, we can compute the following measure for prefix yi:
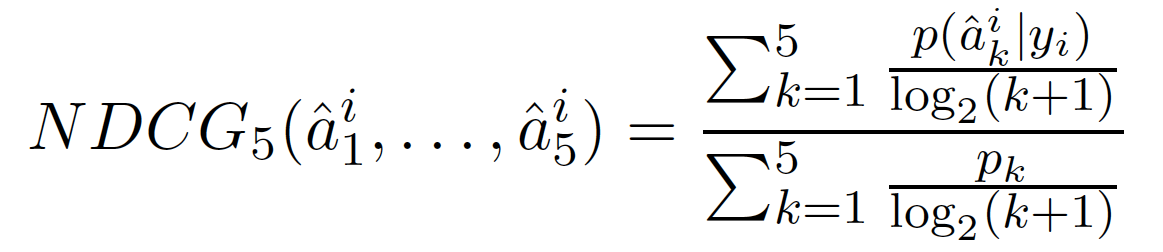
where p1 ≥ p2 ≥ ... ≥ p5 are the top 5 values in the distribution p(.|yi).
The distributions p(.|yi) is computed differently depending on whether the data is synthetic (and the model that generated it is available) or real.
For synthetic data we will use the true conditional distribution over the next symbol.
For real data, where the string yi is obtained as a prefix of a longer string yiax, we will take p(a'|y) = δa=a'. Note that in this case we have p1=1 and p2= ... = p5 = 0.
Thus, when applying this metric to real data we will get NDCG5(â1,...,â5) = 1/log2(j+1), where j is such that âj = a (and j = ∞ if a is not in the list of predicted next symbols).
The score of a submission is the sum of the scores on each prefix in the test sample, normalized by the number of prefixes in the test set.
How the Synthetic Data are generated
We are not going to tell you how the synthetic data are generated. All we can say is that we are using different approaches and models and that we are trying to have synthetic data that "look like" as much as possible to the real-world data. This last point means we computed different statistical measures on the real data and are generating synthetic ones whose characteristics are closed.
How the Real world data are obtained
Yes, there are some real data from the real world! They correspond to problems in different fields from Natural Language Processing to Software Testing, including Biology, User Modelling, and even Sport Scooting!
We preprocessed these data in order to make it difficult to guess what the initial data sets were. But we took extreme care to not modified their essence!
How the datasets are generated
The train and test (both private and public) files are generated randomly using the same process. And that is all we are going to tell you :-)
Why it is forbidden to create several accounts
One of the drawback of on-line competitions is that organizers have to give test samples beforehand. This could have for consequence that the winners might not have the best approach but manage to overfit in a smart way the test sample. However, machine learning algorithms often need a tuning phase. This is why we created 2 test samples: one called 'public' on which you can tune your algorithms (submitting as many times you want and receiving a feedback): it can be seen as a validation set; a second one called 'private' where you only have one shot: once you have submitted your rankings on this sample, you cannot compete on this problem anymore.
Of course, this process is totally useless if you are allowed to create several accounts: you may store the prefixes of the private test sample and tune your algorithm on it. We thus will be very strict on this rule: any team that will not comply with it will be thrown away of the challenge.
What are the possible symbols for ranking?
The possible next symbols are the ones in the train samples: they are integers between 0 and the number of symbols minus 1. However, there is a special symbol that can be given for ranking: -1. It corresponds to the end of sequence symbol. Having seen a prefix yi, the probability of symbol -1 is the probability of yi to be a complete sequence. For instance, if your model tells you that yi is more likely to be a complete sequence than a prefix of a sequence starting with yia, for any possible a, then your ranking should start with -1.
What if I submit my ranking in a wrong format
Depending on what you submit, several cases can happen:
- The format does not allow the computation of the score (for instance, if spaces are used instead of '%20' or you use characters that cannot be translate into interger). Then you will get an error: the file will start with [Error] followed by a temptative of explanation of the problem.
- You submit less or more than 5 possible symbols. Then the system will take into account only the first 5 symbols to compute the score.
- You submit several times the same symbols. Then the score will be computed using only the first occurence of the symbol. For instance, if you submit "3 3 4 5 4", the system will consider that '3' is the first symbol submitted, '4' the third and '5' the fourth; the score will be computed using this information and considering that you do not provide a second and a fifth symbols.
What is the File format?
The format of the training files is the same than for PAutomaC competition: each file starts with a line containing first the number of sequences in the set and then the number of different symbols of the problem; each following lines correspond to one sequence, the first element of the line being the number of elements in the sequence (which allows the empty sequence made of 0 element) and then comes the sequence, element by element, separated by spaces (each element being an integer between 0 and the size of the alphabet minus 1).
The format of the test files is rather simple: they contain a unique line corresponding to the first prefix of the test set, using the same format than the sequences of the train sets: the first element of the line being the number of elements in the prefix (its length in the formal language terminology) and then comes the prefix, element by element, pairwise separated by a space.
